Imagine you ask an AI model, "Paris is widely visited because of" and it responds:
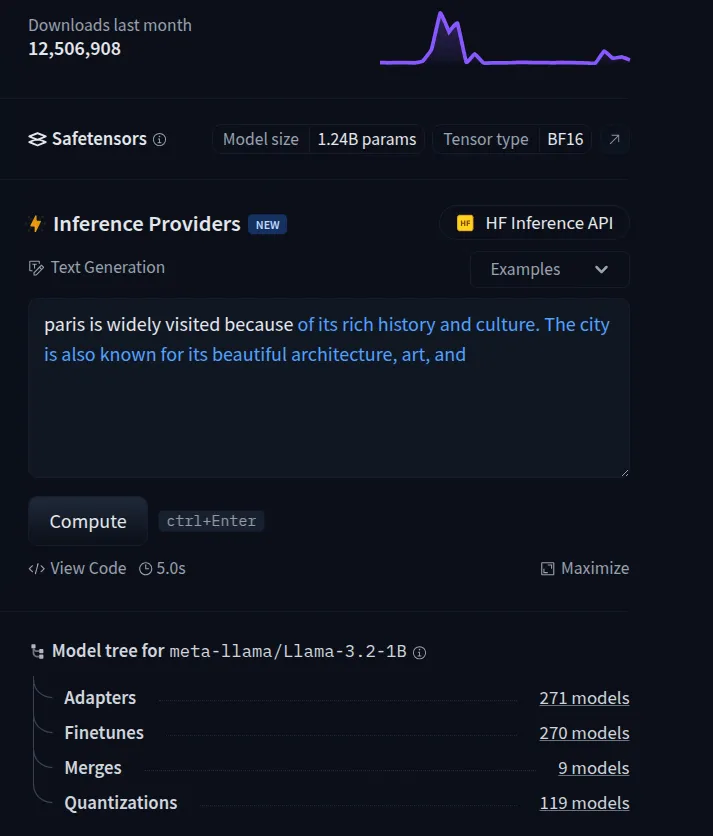
Paris is widely visited because of its rich history and culture. The city is also known for its beautiful architecture, art, and…
At first glance, this answer appears reasonable — after all, Paris is famous for these things. But is this truly knowledge, or just advanced auto-completion?
Lets ask this same question in a different way. Let's ask "Why Paris is widely visited?"
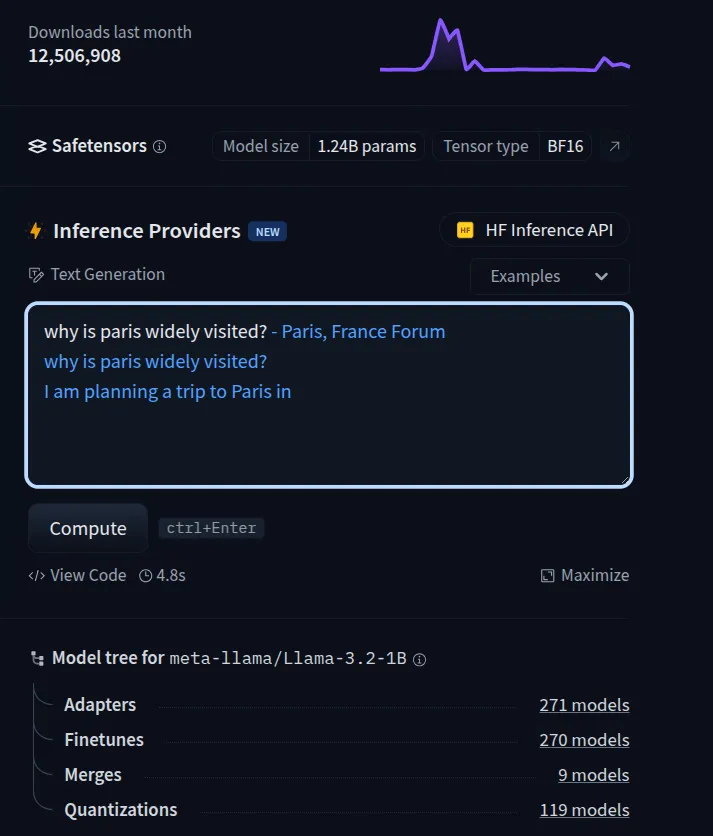
See, it loses track. The reason behind this is that the LLM model I have used above is the meta-llama-3.2–1B base model (a model not specifically fine-tuned to answer questions like an assistant), which relies entirely on predicting statistically likely sequences of words without genuine understanding, making it prone to generating misleading or irrelevant information (hallucinations).
If we dig deeper, it will be clear that LLM doesn't actually "know" anything about Paris. It wasn't drawing from genuine understanding of history, culture, or travel trends. Instead, it simply predicts the next likely words based on patterns of extensive pre-existing text.
How Human Brains Store and Recall Knowledge?
Human brains store knowledge in different areas. Whenever we recall something, our brains dynamically adjust neural connections to store and retrieve information. The more we recall something, the stronger the memory becomes.
How LLMs differ from it?
LLMs (Large Language Models), however, are based on a neural network architecture called transformers. They are trained on vast amounts of text from the internet, books, articles, and more. During training, they learn word patterns by predicting the next word given previous ones. Repeating this on billions of words allows LLMs to generate coherent text.
Do LLMs "Know" Things?
Fundamentally, an LLM is a probability machine. Given a prompt, it calculates the probability of each possible next word. Consider this simplified example:
Given the input: "The sky is…"
The model predicts:
- "blue" (85% probability)
- "gray" (10%)
- "falling" (3%)
- "delicious" (0.01%)
"Blue" is chosen because it has the highest probability. This process repeats, forming coherent sentences. However, the AI isn't reasoning; it simply continues linguistic patterns, sometimes resulting in incorrect or misleading "hallucinations."
Bigram Model…
The most basic language model, which can help us intuitively understand this phenomenon, is a bigram model. It predicts the next word only based on the immediately preceding word. In other words, it assumes each word depends only on the word that directly comes before it.
The formula to calculate bigram probability is:
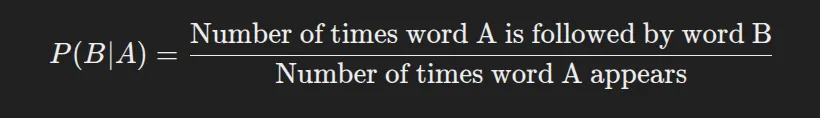
For example, Consider the sentence:
"I love ice cream and I love chocolate."
We first count how often each word occurs:
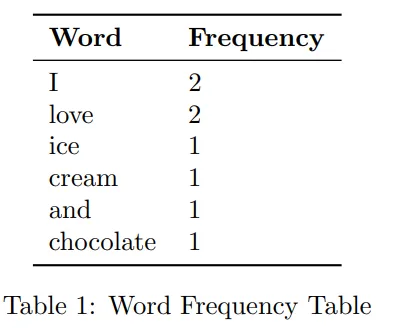
then how often each word pair occurs:
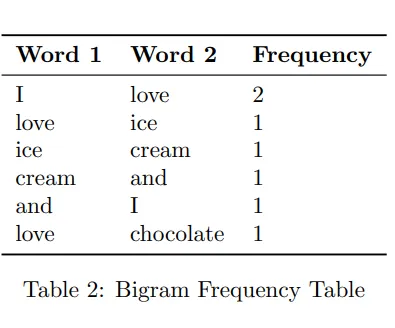
From this, we calculate probabilities:
- Probability of "love" after "I": 2/2 = 1.0 (100%)
- Probability of "chocolate" after "love": 1/2 = 0.5 (50%)
- Probability of "and" after "chocolate": 0/1 = 0 (0%)
This clearly shows how simple text prediction or autocomplete works by using statistical patterns.
Conclusion
Unlike humans, who learn through experience and reasoning, LLMs rely solely on statistical word prediction. They do not retrieve factual answers but generate statistically likely text based on training data. This makes critical thinking and expert verification essential for understanding the depth of any content.
Companies like OpenAI, Deepmind, and xAI are improving their LLMs with "deep research" modules to reduce hallucinations. However, even advanced models still produce misleading or irrelevant data due to their retrieval-augmented generation next-word prediction approach, reinforcing the need for human oversight in critical decisions.
By recognizing AI as a tool rather than a source of truth, we can maximize its benefits while mitigating misinformation risks. Understanding its limitations ensures that real knowledge and critical thinking remain central to progress.